Objektorientierte Programmierung ist häufig immer noch ein rotes Tuch für viele. Man weiß zwar, wie Methoden aufgerufen werden und dass ein Objekt mit CREATE OBJECT oder NEW erzeugt werden muss aber die Designprinzipien sind irgendwie unklar. Und SAP-Klassen sind eh unantastbar.
In diesem Artikel möchte ich dir eine Möglichkeit vorstellen, wie du den SAP-Standard mit Standardmitteln, nämlich mit Hilfe der Vererbung, erweitern kannst.
Enjoy und Bedienung
Trotz der GUI-Elemente, die unter dem Schlagwort ENJOY eingeführt wurden, sind viele Elemente immer noch nicht wirklich benutzerfreundlich. Einiges kann man ändern, anderes nicht. Eine Möglichkeit um mit Hilfe der SAP-Standardcontrols ein neues Look & Feel zu erzeugen, habe ich in diesem Beitrag gezeigt: Moderne UI mit altem SAPGUI und ALV-Grid
Hier habe ich das Standard-ALV-Grid verwendet, um eine neue Funktionalität zu erzeugen. Dies ist allerdings ein eigenständiges Objekt und erweitert nicht die Standardfunktionalität des ALV-Grids.
Wie das Überschreiben von geschützten Methoden generell funktioniert, habe ich hier beschrieben: Geschützte Methoden nutzen
Dieser Artikel soll zeigen, dass es sich eventuell lohnt, auch über andere Erweiterungen von SAP-Standardfunktionalitäten nachzudenken. Es gibt Funktionalitäten, die eventuell in jedem ALV-Grid hilfreich wären. Zum Beispiel das einfache Umsortieren von Einträgen.
Umsortierung mittels Drag & Drop
Eine Möglichkeit ist die Sortierung mittels Drag&Drop im ALV-Feldkatalog:
![]()
Die Bedienung ist hier zwar auch gewöhnungsbedürftig, denn ein Eintrag, der umsortiert werden soll, muss erst mit einem Klick markiert und kann dann erst mittels Drag & Drop an eine andere Stelle verschoben werden, aber immerhin.
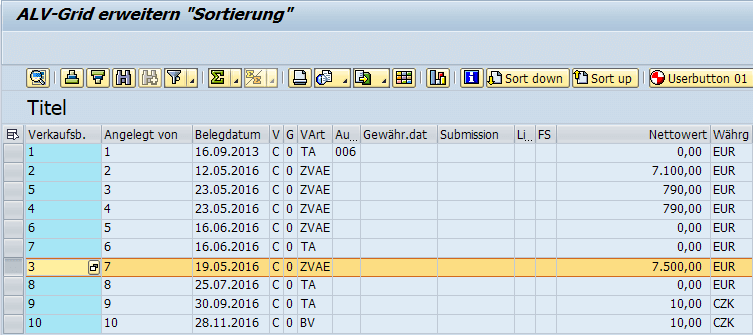
Umsortierung mit Funktionstasten
Eine andere Möglichkeit wäre das Verschieben von Einträgen mit Funktionstasten. Folgender Screenshot ist aus dem unten stehenden Demo-Programm. Das ALV-Grid wurde um die Funktionstasten „Sort Up“ und „Sort Down“ erweitert.
![]()
Wie das im Einzelnen geht, erkläre ich gleich.
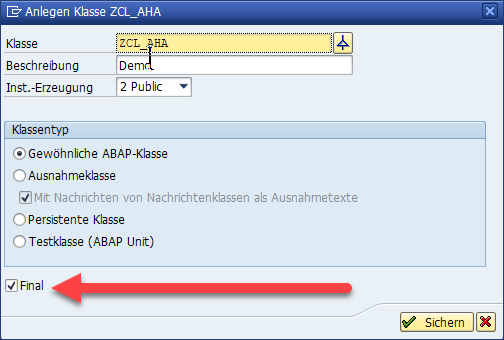
Redefinition
eine wirklich starke Waffe des objektorientierten Sprachumfangs ist die Vererbung. Sofern die anzupassende Klasse nicht als „Final“ definiert wurde, können geschützte und öffentliche Methoden redefiniert werden. Leider wird bei Anlage einer Klasse das Kennzeichen „Final“ vorbelegt, so dass der Programmierer dieses aktiv entfernen muss. Ist dieses Kennzeichen gesetzt, funktioniert die Ableitung bzw. Vererbung nicht.
![]()
Die Klasse CL_GUI_ALV_GRID allerdings darf vererbt werden, denn sie ist nicht als final gekennzeichnet. Nichts desto Trotz muss bei Klassen sehr genau definiert werden, welche Methoden vererbt werden dürfen und welche nicht.
Funktion „Umsortieren“
Die neue Funktion nenne ich „Umsortieren“, denn es ist keine Sortieren-Funktion, die man aus dem Standard kennt. Um Einträge umsortieren zu können, wird in der Regel im SAP mit einem Sortierfeld gearbeitet, das der Anwender manuell pflegen muss. Dazu wird häufig in Zehnerschritten gearbeitet, um später Einträge einfügen zu können. Einträge in dieser Form in eine andere Reihenfolge zu bringen ist in der Regel sehr mühselig.
Die Idee ist, dass der Anwender einen Eintrag markieren kann und diesem mit den Funktionstasten „Sort Up“ und Sort Down“ in der Liste hoch und runter verschieben kann. Ein Feld, in der die aktuelle Reihenfolge festgehalten wird, brauchen wir natürlich trotzdem.
Vererbung
Ich möchte die Klasse CL_GUI_ALV_GRID also für meine Zwecke missbrauchen und muss sie deswegen ableiten bzw. vererben. Dazu lege ich in der Transaktion SE80 oder SE24 eine neue Klasse an: ZCL_GUI_ALV_GRID_SORT und gebe als Oberklasse zu zu beerbende Klasse CL_GUI_ALV_GRID an:
![]()
Sortierfeld
Der Programmierer muss angeben können, welches Feld für die Sortierung der Einträge verwendet werden soll. In diesem Feld wird dann die automatische Nummerierung anhand der Reihenfolge gesetzt. Ich lege dafür die Methode SET_SORT_FIELD an mit dem Übergabeparameter FIELDNAME.
Diese Methode muss vor SET_TABLE_FOR_FIRST_DISPLAY aufgerufen werden, damit die Umsortierfunktionalität von Anfang an zur Verfügung steht.
Das Sortierfeld merke ich mir im Attribut MV_SORT_FIELD.
Ereignis TOOLBAR
Da ich das Ereignis TOOLBAR nutzen möchte, um die neuen Funktionstasten einzubauen, muss ich es für meine abgeleitete Klasse registrieren:
SET HANDLER on_toolbar FOR me.
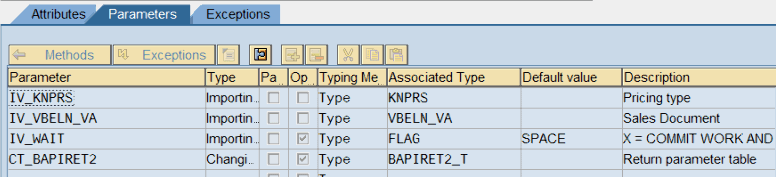
Zusätzlich benötige ich eine Methode, die beim Auslösen des Ereignisses angesprungen wird: ON_TOOLBAR. Diese Methode muss als Ereignisbehandler für das Ereignis TOOLBAR definiert werden:
![]()
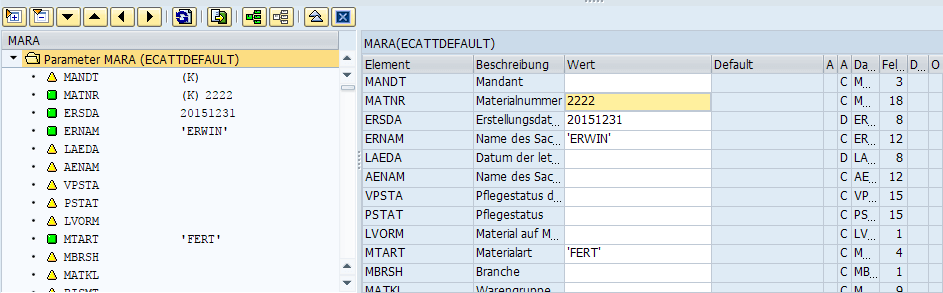
Der Methode stehen nun theoretisch alle Parameter des Ereignisses zur Verfügung. Allerdings müssen diese manuell übernommen werden. Die Drucktaste „Ereignisparameter“ in der Sicht „Parameter“ erledigt das für mich:
![]()
In der Methode füge ich die Drucktasten SORT_UP und SORT_DOWN der Toolbar hinzu.
METHOD on_toolbar.
check mv_sort_field is NOT INITIAL.
APPEND VALUE #( function = 'Sort_down'
icon = icon_next_page
quickinfo = space
butn_type = if_sat_ui_button_types=>normal
disabled = space
text = 'Sort down'
checked = space ) TO e_object->mt_toolbar.
APPEND VALUE #( function = 'Sort_up'
icon = icon_previous_page
quickinfo = space
butn_type = if_sat_ui_button_types=>normal
disabled = space
text = 'Sort up'
checked = space ) TO e_object->mt_toolbar.
ENDMETHOD.
Redefinition DISPATCH
Um intern auf die Drucktasten reagieren zu können, muss ich die Methode DISPATCH redefinieren und meine Drucktasten SORT_UP und SORT_DOWN für das Ereignis TOOLBAR_BUTTON_CLICK abfangen.
In allen anderen Fällen muss die Methode DISPATCH der abgeleiteten Klasse aufgerufen werden (SUPER->DISPATCH).
Im Falle des Ereignisses TOOLBAR_BUTTON_CLICK muss ich mir noch die Ereignisparameter besorgen in denen der Funktionscode der Drucktaste steht (Methode GET_EVENT_PARAMETER).
Nun gilt es noch, folgendes zu tun:
- Abfrage auf die Funktionscodes SORT_UP und SORT_DOWN
- Zugriff auf die Datentabelle erhalten
- Ermitteln der aktuellen Cursorposition
- Umsortieren des Eintrags
- Neunummerierung
- Cursor auf die umsortierte Zeile setzen
- Anzeige aktualisieren
METHOD dispatch.
DATA action TYPE string.
CASE eventid.
WHEN evt_toolbar_button_click.
CALL METHOD get_event_parameter
EXPORTING
parameter_id = 0
queue_only = space
IMPORTING
parameter = action.
CALL METHOD cl_gui_cfw=>flush.
CASE action.
WHEN 'Sort_up'.
CALL METHOD get_current_cell
IMPORTING
es_row_id = DATA(ls_row)
es_row_no = DATA(ls_row_no).
FIELD-SYMBOLS <outtab> TYPE table.
ASSIGN mt_outtab->* TO <outtab>.
IF ls_row-index > 1.
READ TABLE <outtab> ASSIGNING FIELD-SYMBOL(<outline>) INDEX ls_row-index.
DATA(indx) = ls_row-index - 1.
ASSIGN COMPONENT 2 OF STRUCTURE <outline> TO FIELD-SYMBOL(<value>).
IF sy-subrc = 0.
INSERT <outline> INTO <outtab> INDEX indx.
indx = indx + 2.
DELETE <outtab> INDEX indx.
indx = indx - 2.
LOOP AT <outtab> ASSIGNING <outline>.
ASSIGN COMPONENT mv_sort_field OF STRUCTURE <outline> TO <value>.
<value> = sy-tabix.
ENDLOOP.
refresh_table_display( is_stable = VALUE #( col = abap_true row = abap_true ) i_soft_refresh = abap_true ).
set_selected_rows( it_row_no = VALUE #( ( row_id = indx ) ) ).
ENDIF.
ENDIF.
EXIT.
WHEN 'Sort_down'.
CALL METHOD get_current_cell
IMPORTING
es_row_id = ls_row
es_row_no = ls_row_no.
ASSIGN mt_outtab->* TO <outtab>.
IF ls_row-index < lines( <outtab> ).
READ TABLE <outtab> ASSIGNING <outline> INDEX ls_row-index.
indx = ls_row-index + 2.
ASSIGN COMPONENT 2 OF STRUCTURE <outline> TO <value>.
IF sy-subrc = 0.
INSERT <outline> INTO <outtab> INDEX indx.
indx = indx - 2.
DELETE <outtab> INDEX indx.
indx = indx + 1.
LOOP AT <outtab> ASSIGNING <outline>.
ASSIGN COMPONENT mv_sort_field OF STRUCTURE <outline> TO <value>.
<value> = sy-tabix.
ENDLOOP.
refresh_table_display( is_stable = VALUE #( col = abap_true row = abap_true ) i_soft_refresh = abap_true ).
set_selected_rows( it_row_no = VALUE #( ( row_id = indx ) ) ).
ENDIF.
ENDIF.
EXIT.
ENDCASE.
ENDCASE.
super->dispatch(
EXPORTING
cargo = cargo
eventid = eventid
is_shellevent = is_shellevent
is_systemdispatch = is_systemdispatch
EXCEPTIONS
cntl_error = 1
OTHERS = 2 ).
ENDMETHOD.
Testprogramm
In folgendem Testprogramm kannst du die Verwendung des neuen Standards sehen. Du siehst, dass trotz meines Eingriffs in die Toolbar weiterhin Drucktasten hinzugefügt werden können:
REPORT zz_alv_grid_sort.
DATA gs_data TYPE vbak.
SELECT-OPTIONS s_vbeln FOR gs_data-vbeln.
CLASS main DEFINITION.
PUBLIC SECTION.
TYPES ty_data TYPE vbak.
TYPES ty_data_t TYPE STANDARD TABLE OF ty_data
WITH DEFAULT KEY.
DATA ms_data TYPE ty_data.
DATA mt_data TYPE ty_data_t.
DATA mr_grid TYPE REF TO zcl_gui_alv_grid_sort.
METHODS start.
PROTECTED SECTION.
METHODS selection.
METHODS display.
METHODS handle_toolbar FOR EVENT toolbar
OF cl_gui_alv_grid
IMPORTING e_object.
METHODS handle_user_command FOR EVENT user_command
OF cl_gui_alv_grid
IMPORTING e_ucomm sender.
ENDCLASS.
CLASS main IMPLEMENTATION.
METHOD handle_user_command.
DATA lt_rows TYPE lvc_t_row.
DATA ls_row TYPE lvc_s_row.
DATA ls_data TYPE ty_data.
CASE e_ucomm.
WHEN 'USER01'.
sender->get_selected_rows( IMPORTING et_index_rows = lt_rows ).
LOOP AT lt_rows INTO ls_row.
READ TABLE mt_data INTO ls_data INDEX ls_row-index.
IF sy-subrc = 0.
MESSAGE i000(oo) WITH 'Usercommand 01: Beleg' ls_data-vbeln.
ENDIF.
ENDLOOP.
ENDCASE.
ENDMETHOD.
METHOD handle_toolbar.
DATA: ls_toolbar TYPE stb_button.
*** Trenner
CLEAR ls_toolbar.
MOVE 3 TO ls_toolbar-butn_type.
APPEND ls_toolbar TO e_object->mt_toolbar.
*** Icon “Test”
CLEAR ls_toolbar.
MOVE icon_generate TO ls_toolbar-icon.
MOVE 'USER01' TO ls_toolbar-function.
MOVE 'User 01' TO ls_toolbar-quickinfo.
MOVE 'Userbutton 01' TO ls_toolbar-text.
APPEND ls_toolbar TO e_object->mt_toolbar.
ENDMETHOD.
METHOD start.
selection( ).
display( ).
ENDMETHOD.
METHOD selection.
SELECT * FROM vbak INTO TABLE mt_data UP TO 10 ROWS.
ENDMETHOD.
METHOD display.
WRITE 'DUMMY'.
CREATE OBJECT mr_grid
EXPORTING
i_parent = cl_gui_container=>screen0
i_appl_events = space.
mr_grid->set_sort_field( 'ERNAM' ).
SET HANDLER handle_toolbar FOR mr_grid.
SET HANDLER handle_user_command FOR mr_grid.
DATA lv_structure_name TYPE dd02l-tabname VALUE 'VBAK'.
DATA ls_variant TYPE disvariant.
DATA lv_save TYPE char01 VALUE 'U'.
DATA lv_default TYPE char01 VALUE abap_true.
DATA ls_layout TYPE lvc_s_layo.
ls_layout-sel_mode = 'A'.
ls_layout-grid_title = 'Titel'.
mr_grid->set_table_for_first_display(
EXPORTING
i_structure_name = lv_structure_name
is_variant = ls_variant
i_save = lv_save
i_default = lv_default
is_layout = ls_layout
CHANGING
it_outtab = mt_data ).
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
NEW main( )->start( ).
Ergebnis
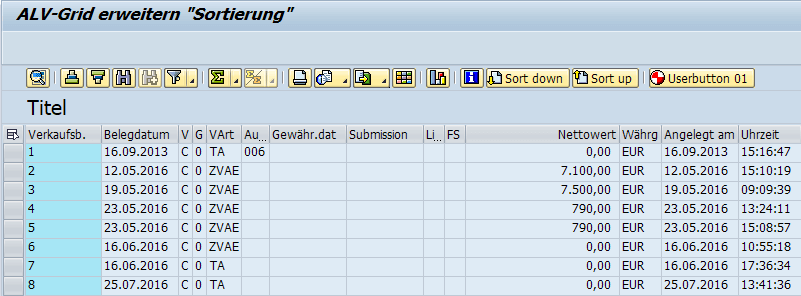
Du kannst nun den Cursor auf einen Eintrag stellen und durch Klicken auf „Sort Up“ oder „Sort Down“ den Eintrag umsortieren. Die Sortierung wird in dem Feld „ERNAM – Angelegt von“ vorgehalten.
![]()
Fazit
Die Änderung von SAP-Standardfunktionen ist möglich. Allerdings ist das erstens nicht immer so einfach, wie in diesem Artikel beschrieben. In der Regel muss man genau und langwierig debuggen und prüfen, wo welche Methoden verwendet werden können. Zudem müssen die Funktionen natürlich ausgiebig getestet werden. Immerhin sollen sie genau wie die Standardfunktionalität zuverlässig funktionieren.
Des Weiteren sollten Funktionen, die wirklich in einer Vielzahl von eigenen Programmierungen eingesetzt werden sauber ausprogrammiert werden. In dem hier vorgestellten Beispiel sollte zum Beispiel sichergestellt werden, dass das Feld mit der Sortierung auch wirklich im Feldkatalog vorhanden ist. Die Benutzereigene Sortierung muss irgendwie berücksichtigt werden.
Zudem sollte es natürlich möglich sein, auch mehrere Zeilen zu markieren und diese en bloc zu verschieben. Das hängt aber wiederum von der Programmierung ab, ob wirklich mehrere Zeilen markiert werden dürfen oder nicht.
Ebenso wäre die Eingangs erwähnte Sortierung mittels Drag & Drop sinnvoll. Diese könnte dann allerdings einer anderen vom Programmierer erstellten Drag & Drop Funktionalität in die Quere kommen.
Allerdings lohnt es sich, hier Aufwand zu investieren, denn die erweiterte Funktionalität kann eventuell viele separate Programmierungen überflüssig machen oder vorhandene Programmierungen auf einfache Weise benutzerfreundlicher machen.
Der Beitrag ALV-Grid um Sortierfunktion erweitern (Vererbung) erschien zuerst auf Tricktresor.